

近日,APUS与深圳大学大数据系统计算技术国家工程实验室(以下简称“大数据国家工程实验室”)联合训练伶荔Linly-70B中文大模型,并在GitHub上正式首发开源,这是APUS大模型3.0的首个开源大模型。

据了解,APUS大模型3.0伶荔在中文基准测评榜单C-Eval上评分80.6分,中文能力超越GPT-4,在所有参评模型中排名第三,相比原始开源模型标杆LLaMa2-70B取得了大幅提升。
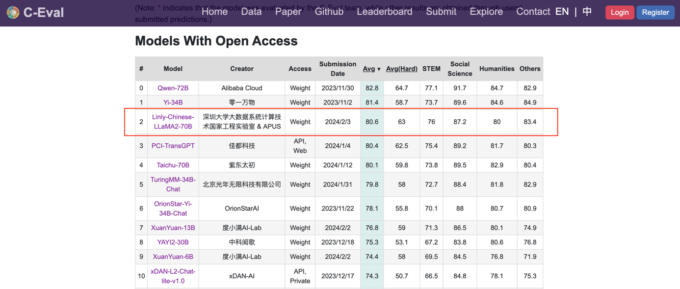
值得注意的是,大数据国家工程实验室由深圳大学牵头,与国家信息中心、清华大学和腾讯科技等联合建设;更有中国科学院陈国良院士、国家重点研发项目首席科学家李坚强等一批拔尖人才组成研发组,实验室副主任沈琳琳教授领导的伶荔项目团队支撑了此次模型的联合训练和开源发布。
此次APUS与大数据国家工程实验室联合训练开源的APUS大模型3.0伶荔中文大模型,进一步推动了AI技术创新与国内场景应用深化融合。“伶荔是国内仅有的几家700亿参数规模的中文开源大模型之一,相信能让更多国人开发者参与到人工智能产业大潮中。”伶荔项目团队李煜东博士如此表示。
可以看到,APUS大模型3.0伶荔中文大模型在词表大小、训练语料等方面进行了定制化调优,基于模块化增量预训练框架开发,针对中文场景扩充词表,增加汉字和中文符号支持,实现综合性能达到同量级开源模型的领先水平。在语料训练上,APUS大模型3.0伶荔采用高质量中英文公开数据源包括悟道、万卷、MNBVC等,并结合自研数据选择策略,构成模型高效训练的混合语料库。基于APUS郑州智算中心的算力支持,APUS大模型3.0伶荔耗时3个月完成训练,当前上下文长度设定为4K(约8000-10000汉字)。
此外,伶荔项目团队还提出课程学习策略,基于动态数据采样,在训练中调整数据的分布,实现将模型的英文语言能力平稳迁移学习到中文能力领域,为训练出高性能中文大模型提供有力保障。
随着APUS大模型3.0伶荔的联合发布、开源,国产开源大模型向构建中文场景大型语言模型又迈出了重要一步。此次合作也是双方深化践行“为中国定制人工智能大模型,积极构建人工智能生态,让大模型应用和价值创造接轨”战略的重要举措。
据悉,APUS还将与大数据国家工程实验室持续推动模型的能力提升和应用拓展,积极探索深化大模型在工具使用、剧情生成和角色扮演、医疗等领域的专业能力,聚力构建大模型生态,让为中国打造的AI大模型真正驱动中国AI产业高质量发展,实现价值共创,赋能千行万业。